绝大多数 AI 芯片设计团队正在利用传统的数字电路设计技术,寻求提供硬件加速,以实现高能效、高吞吐量和低时延的 DNN 计算,同时避免牺牲神经网络精度。不管在系统级还是在芯片级,他们都大量采用异质架构,如 CPU 加 GPU、CPU 加 FPGA,或在 FPGA 里再增加「AI 引擎」(赛灵思公司)等。对 AI 芯片研发人员而言,了解并考虑这些数字加速器不断取得的进展至关重要。
DNN 将神经元排列成一层,这样排列后的网络层多达数十层、几百层甚至更多,逐层推理输入数据的更抽象的表示,最终达成其结果,如实现翻译文本或识别图像。每层都被设计用于检测不同级别的特征,将一个级别的表示(可能是图像、文本或声音的输入数据)转换为一个更抽象级别的表示。例如,在图像识别中,输入最初以像素的形式出现;第一层检测低级特征,如边缘和曲线;第一层的输出变为第二层的输入,产生更高级别的特征,如半圆形和正方形;后一层将前一层的输出组合为一部分熟悉的对象,后续层检测对象。随着经过更多的网络层,网络会生成一个代表越来越复杂特征的激活映射。网络越深,卷积核所能响应的像素空间中的区域就越大。
在各种神经网络类型中,卷积神经网络(CNN)被认为是计算机视觉领域最具潜力的创新之一,在分类和各种计算机视觉任务方面准确性更高。因此,现在的主流深度学习都以 CNN 作为最主要的部分,这也是现在很大一部分深度学习应用在图像识别、图像分类等领域的原因。包含 CNN 在内,目前比较流行的 DNN 及其主要特征如下。
(1)卷积神经网络(CNN):前馈型,权重共享,稀疏连接;
(2)全连接(Fully Connected,FC)神经网络:前馈型,又称多层感知器(MLP);
(3)循环神经网络(RNN):反馈型;
(4)长短期记忆网络(LSTM):反馈型,具备存储功能。
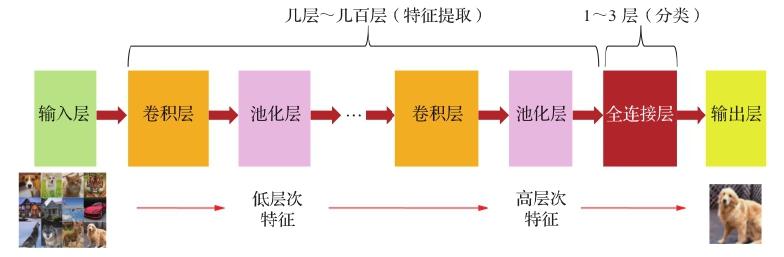
目前大部分 DNN 的基本组成,主要是 CNN 卷积层(CONV 层)加上少量全连接层(FC 层)及池化层等,如图 3.1 所示。


 正在加载...
正在加载...