现在,人脸识别技术已经非常普及,并已成为 AI 的重要应用之一。如果 AI 可以归纳分类出每个人的人脸,那么能否让 AI 根据人脸的特征创造出人脸,或根据照片创作出一幅有特定风格的艺术画作呢?
自 2014 年伊恩·古德费洛(Ian J. Goodfellow) [207] 等人发明了 GAN 之后,GAN 作为一种强大的无监督学习方法得到了迅猛发展。它是《麻省理工科技评论》(MIT Technology Review)报告的 2018 年十大突破性技术之一。GAN 在图像生成、视频预测和自动驾驶等许多领域中已开始发挥重要作用,成为当前的热点。基于 GAN 算法的产品甚至已经得到了商业化应用。
利用 GAN 算法,可以让 AI 学习和模仿几乎任何数据分布,因此可以被训练在很多领域中创作,如图像、音乐、演讲、小说、散文、诗歌等,其作品能做到与现实世界极其相似。因此,GAN 可以部分解决人类智能中很关键的创造性问题。GAN 被很多研究人员称为「下一代 AI 算法」,因为它不仅能够用于识别和分类,而且可以生成和联想,这就让 AI 迈向人类智力水平的征程又上了一个台阶。
GAN 由两个 DNN 组成,即一个生成器 G 和一个鉴别器 D,这两个模型相互竞争、相互加强。与传统的神经网络不同,GAN 采用博弈论方法,能够通过双人博弈从训练分布中生成目标。由于应用了对抗性学习方法,训练过程不需要近似难以处理的概率分布函数。此外,使用生成器的时候,只需用随机数驱动它。由于对用作 G 和 D 的 DNN 类型没有限制,因此可以根据要生成的数据和目的来选择适当类型的 DNN。例如,生成图像时,可以选用对图像处理非常有效的 CNN,而如要生成时间序列数据的语音和文本,则选 RNN 或 LSTM(见图 11.6)。
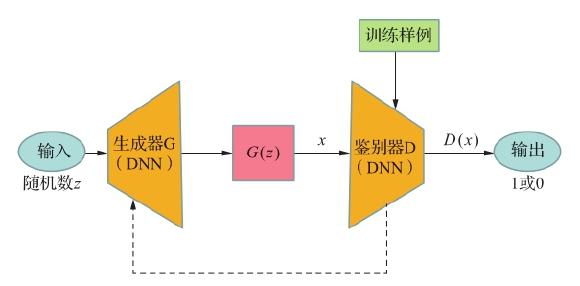 图 11.6 GAN 的构成
图 11.6 GAN 的构成
GAN 可以被看作反向的深度学习识别器。在用于图
(本章节未完结,点击下一页翻页继续阅读)


 正在加载...
正在加载...