目前的计算系统,包括智能手机在内,都是基于冯·诺依曼架构,即处理单元与存储器是物理上分开的,面临着大量数据在处理单元和存储器之间来回移动所产生的能耗和时延问题,这有时被称为「内存墙」。这个问题在一些由 AI 加速器芯片组成的 AI 系统中已经成为一个严重的计算效率瓶颈。根据在 AI 推理芯片上的测试 [120] ,单个整数 MAC 操作可能仅需要约 3.2 pJ 的能量,但如果将权重值存储在片外 DRAM 中并送至处理器进行计算,则仅获取卷积核值就需要约 640 pJ 的能量。这个问题在深度学习算法的训练阶段更加普遍,在这个阶段,必须学习或频繁更新数亿个权重值。存储器访问的能量消耗将使整体的计算不堪重负。
如图 7.1 所示,当前的数字计算机由执行操作的处理器和将数据及程序存储在单独芯片中的主存储器组成。这些芯片通过数据总线连接,形成了冯·诺依曼架构的基本配置。随着处理器和存储器变得速度更快并且功耗降低,由总线中充电和放电的布线容量引起的对通信带宽的限制和功耗增加已经变得突出,这就是所谓的冯·诺依曼瓶颈。
为了缓解这种情况,如图 7.1 中右图所示,大量的小型处理单元和本地存储器并行连接到 GPU 或专用 AI 处理器中的芯片上,这种直接在存储器上执行操作的方法称为存内计算。在由交叉开关阵列组成的 NVM 中,模拟权重值被本地存储在交叉开关器件中,以最大限度地减少训练过程中的数据移动。一些实验结果表明,使用合适的存内计算,可以将训练速度提高 4 个数量级以上。存内计算也使得一些边缘侧设备可以启用更复杂的推理算法。
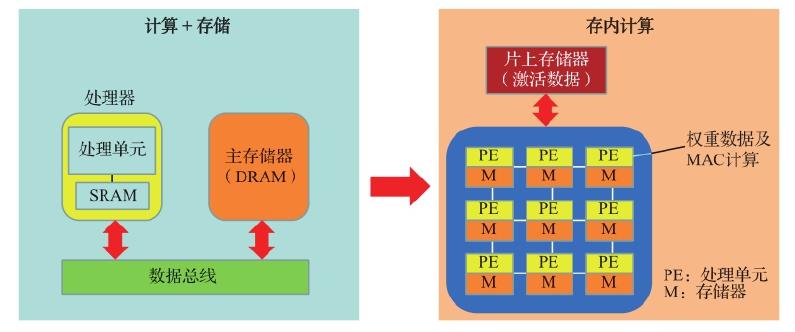 图 7.1 从冯·诺依曼架构(左)到存内计算架构(右)
图 7.1 从冯·诺依曼架构(左)到存内计算架构(右)
虽然存内计算这个想法已经提出至少 40 年了,但是这种方法过去没有被大规模商业应用,而是在近 10 年才越来越得到产业界的重视,其主要原因有以下几个方面。
(1)存储技术没有像
(本章节未完结,点击下一页翻页继续阅读)


 正在加载...
正在加载...